


最近、ハードウェアRAID1エンクロージャでmdを含む2台のeSATAドライブを使用するように切り替えました。ディレクトリの巡回/リストが時々クロールされる点(約10秒かかります)を除いて、すべてがうまくいくようです。私はブロックサイズが4Kに設定されたext3ファイルシステムを使用しています。
いくつかの重要なコマンドの関連出力は次のとおりです。
mdadm - 詳細情報:
/dev/md127:
Version : 1.2
Creation Time : Sat Nov 16 09:46:52 2013
Raid Level : raid1
Array Size : 976630336 (931.39 GiB 1000.07 GB)
Used Dev Size : 976630336 (931.39 GiB 1000.07 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Tue Nov 19 01:07:59 2013
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Events : 19691
Number Major Minor RaidDevice State
2 8 17 0 active sync /dev/sdb1
1 8 1 1 active sync /dev/sda1
fdisk -l /dev/sd{a,b}:
Disk /dev/sda: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0xb410a639
Device Boot Start End Blocks Id System
/dev/sda1 2048 1953525167 976761560 83 Linux
Disk /dev/sdb: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0x261c8b44
Device Boot Start End Blocks Id System
/dev/sdb1 2048 1953525167 976761560 83 Linux
time dumpe2fs /dev/md127 grep サイズ:
dumpe2fs 1.42.7 (21-Jan-2013)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super large_file
Block size: 4096
Fragment size: 4096
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal size: 128M
real 2m14.242s
user 0m2.286s
sys 0m0.352s
私が理解したところによると、このドライブには4Kセクタがありますが(最も近いWD赤)、パーティション/ファイルシステムが正しく整列しているようです。 mdメタデータバージョン1.2を使用しているようですので、私も大丈夫だと思います。mdadm raid1および4kドライブのブロックサイズ(またはブロックサイズ)はいくらですか?)。私がオンラインで答えを見つけることができなかったことの1つは、256のinodeサイズが問題を引き起こすかどうかです。すべてのタスクが遅いわけではありませんが、バッファキャッシュはタスクをすばやく維持するのに効果的です。
私のカーネルバージョンは3.11.2です。
編集者:新しい情報、2013-11-19
mdadm --examine /dev/sd{a,b}1 | grep -i offset
Data Offset : 262144 sectors
Super Offset : 8 sectors
Data Offset : 262144 sectors
Super Offset : 8 sectors
また、ファイルシステムをマウントするときにnoatime,nodiratimeロギングを処理しすぎることにはあまり興味がありません。 RAID1に十分気を付ければ自滅できるからです。ディレクトリインデックスを開きたい
2013年11月20日修正
昨日私はext3のディレクトリインデックスを開き、e2fsck -D -fそれが役に立ったかどうかを調べるために実行しました。残念ながらそうではありません。私はこれがハードウェアの問題かもしれないと疑い始めました(それともeSATAのmd raid1が本当に愚かなのでしょうか?)。各ドライブをオフラインにして、個々にどのように機能するかを検討することを検討しています。
2013年11月21日修正
iostat -kx 10 |grep -P "(sda|sdb|デバイス)":
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.37 1.17 0.06 0.11 1.80 5.10 84.44 0.03 165.91 64.66 221.40 100.61 1.64
sdb 13.72 1.17 2.46 0.11 110.89 5.10 90.34 0.08 32.02 6.46 628.90 9.94 2.55
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
出力を0.00%に切ります。
私はこれが少し遅い感じではなく、数十秒から1分かかることがあり、タブのオートコンプリートやlsの実行に少しの変更が必要になる可能性があるため、ext4とext3とは何の関係もないはずだと思います。
編集:ハードウェアの問題かもしれません。確認されたら質問を閉じます。
考えればするほどこれがeSATAカードに問題があるのではないかという気がします。私は現在これを使用しています:http://www.amazon.com/StarTech-PEXESAT32-Express-eSATA-Controller/dp/B003GSGMPU しかし、私はちょうどdmesgをチェックしましたが、次のメッセージがあふれました。
[363802.847117] ata1.00: status: { DRDY }
[363802.847121] ata1: hard resetting link
[363804.979044] ata2: softreset failed (SRST command error)
[363804.979047] ata2: reset failed (errno=-5), retrying in 8 secs
[363804.979059] ata1: softreset failed (SRST command error)
[363804.979064] ata1: reset failed (errno=-5), retrying in 8 secs
[363812.847047] ata1: hard resetting link
[363812.847061] ata2: hard resetting link
[363814.979063] ata2: SATA link up 1.5 Gbps (SStatus 113 SControl 10)
[363814.979106] ata1: SATA link up 1.5 Gbps (SStatus 113 SControl 10)
....
[364598.751086] ata2.00: status: { DRDY }
[364598.751091] ata2: hard resetting link
[364600.883031] ata2: softreset failed (SRST command error)
[364600.883038] ata2: reset failed (errno=-5), retrying in 8 secs
[364608.751043] ata2: hard resetting link
[364610.883050] ata2: SATA link up 1.5 Gbps (SStatus 113 SControl 10)
[364610.884328] ata2.00: configured for UDMA/100
[364610.884336] ata2.00: device reported invalid CHS sector 0
[364610.884342] ata2: EH complete
干渉があるのか気になって、より短いシールド型eSATAケーブルも購入する予定です。
答え1
結局ハードウェアの問題になります
新しいシールドケーブルに切り替えても役に立ちませんでしたが、既存のカードを次のものに交換しました。http://www.amazon.com/gp/product/B000NTM9SYエラーメッセージと奇妙な動作を実際に削除しました。変更があると、新しいコンテンツが公開されます。
SATAエンクロージャに関する重要な注意:
上記の操作を実行した後も、ドライブが一定時間アイドル状態にある限り、すべてのドライブの動作は非常に遅くなります(10〜30秒間のみ停止)。私が使っているケースにはeSATAポートがありますが、USBで電源が供給されます。私は回転する力が足りないからと思っていくつか試しました。
- 外部大電流USB電源装置の使用(ポートが少なくとも500mAのみ供給する場合)
- スピンを無効にする
hdparm -S 0 /dev/sdX(これは問題を大幅に軽減しますが、完全には解決しません) - 高度な電源管理を無効にする
hdparm -B 255 /dev/sdX(やはり完全には解決されません)
結局私はWestern Digitalに電力回転を減らすためのジャンパー設定があることを発見しました。特にこのユースケースのために設計されています!
私が使っているハードドライブはWD Red WD10JFCX 1TB IntelliPower 2.5"です。 http://support.wdc.com/images/kb/scrp_connect.jpg
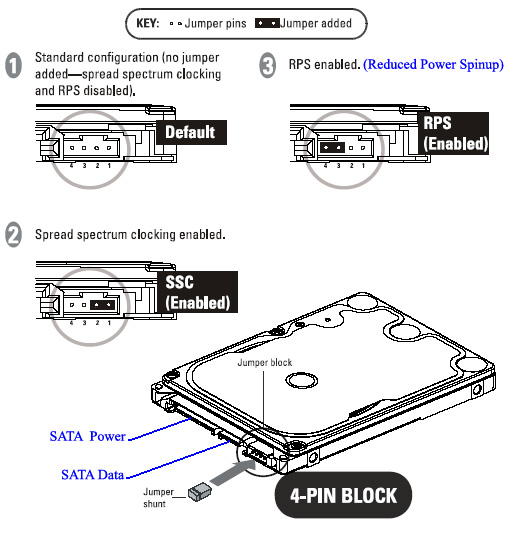{kind=link}
すべての電源管理とスピンダウン機能なしでまだ実行されています(まだhdparm-B 255から)。-S 0
最終評決
残念ながら、RPSは私の問題のすべてを解決せず、振幅と周波数だけを減らしました。結局のところ、問題はケースが十分な電力を供給できないためです(AC-USBアダプタを使用しても)。結局このケースを購入するようになりました。
http://www.amazon.com/MiniPro-eSATA-6Gbps-External-Enclosure/dp/B003XEZ33Y
過去3週間で、すべてのことが順調に行われました。